Alpaca Training Example - Instruction-following LLaMA Model
This tutorial demonstrates how to use the Stanford Alpaca code to fine-tune a Large Language Model (LLM) as an instruction-trained model and use the results for inference on the proxiML platform. Running the entire tutorial as described will consume approximately 40 credits ($40 USD). The credit charge can be decreased by changing some of the training settings. The code for this tutorial is located here.
This tutorial is for research and training purposes only. You must agree to and follow all license terms of the source code, datasets, and model code. In particular, using the results of this tutorial for commercial purposes is prohibited.
Prerequisites
Before beginning this example, ensure that you have satisfied the following prerequisites.
- A valid proxiML account with a non-zero credit balance.
- A python virtual environment with the proxiML CLI/SDK installed and configured.
Instruction Fine-Tuning
The original Alpaca fine-tuning script required 4 GPUs with 80GB of VRAM each. Since these GPUs are unavailable or in highly constrained supply on most cloud platforms, this training example uses Microsoft's DeepSpeed framework to significantly lower the required VRAM for the training process. Deepspeed is installed on all proxiML Python 3.9+ PyTorch environments (including the default Deep Learning environment), with pre-complied extensions/ops.
Using the Zero Stage 2 with optimizer offload and gradient checkpointing, we can successfully train Alpaca on 4 GPUs with 24GB of VRAM each. Although this process takes 3-4 times longer than their original configuration, the $/hour GPU savings of lower VRAM GPUs results in significant total training cost savings (from approximately $100 to less than $40), with the opportunity for additional cost savings.
To create the proxiML Training Job to train Alpaca, run the following command in the Python virtual environment in which you have installed the proxiML CLI/SDK.
proximl job create training \\
--gpu-type rtx3090 \\
--gpu-count 4 \\
--disk-size 50 \\
--public-checkpoint llama-7b \\
--git-uri https://github.com/proxiML/alpaca-llm-fine-tuning-example.git \\
--output-type proximl \\
--output-uri checkpoint \\
--no-archive \\
"Alpaca Training" \\
'deepspeed --num_gpus 4 train.py \\
--model_name_or_path "${ML_CHECKPOINT_PATH}" \\
--data_path "${ML_MODEL_PATH}/alpaca_data.json" \\
--bf16 True \\
--output_dir "${ML_OUTPUT_PATH}" \\
--num_train_epochs 3 \\
--per_device_train_batch_size 16 \\
--per_device_eval_batch_size 16 \\
--gradient_accumulation_steps 2 \\
--gradient_checkpointing \\
--evaluation_strategy "no" \\
--save_strategy "steps" \\
--save_steps 2000 \\
--save_total_limit 1 \\
--learning_rate 2e-5 \\
--weight_decay 0. \\
--warmup_ratio 0.03 \\
--lr_scheduler_type "cosine" \\
--logging_steps 1 \\
--tf32 True \\
--deepspeed "${ML_MODEL_PATH}/ds_config_zero2_offload.json" \\
--report_to none'
This job should take between 10-11 hours and consume 35-40 credits. Once the training job is complete, it will automatically create a checkpoint named Job - <job name>, which in this example's case will be Job - Alpaca Training. Rename the checkpoint to something more succinct with the following command:
proximl checkpoint rename "Job - Alpaca Training" "alpaca"
Reducing Training Duration
The original Alpaca project generated their results using a global batch size of 128 and 3 epochs of training. This tutorial attempts to replicate that process as closely as possible while fitting the fine tuning process into the available memory of 4 RTX 3090s (24 GB * 4). The training duration can be reduced significantly by increasing the gradient_accumulation_steps to 4 or 8, thereby increasing the global batch size to 256 or 512. The effect on the model inference performance metrics has not been evaluated. Using gradient_accumulation_steps of 8 (global batch size of 512) will reduce the training time to approximately 5-6 hours (20-25 credits).
As with any training process, the process can be significantly shortened by reducing the number of epochs. This is certain to have a negative effect on model inference performance. However, if you wish to simply test the model (with no concern for its quality), lowering num_train_epochs to 0.25 will complete training in approximately 1 hour (4 credits).
Deploying an Inference Endpoint
To experiment with model results, deploy a proxiML Endpoint using the newly created checkpoint. The proxiML example repository contains an endpoint deployment script and example React app to interact with the running endpoint.
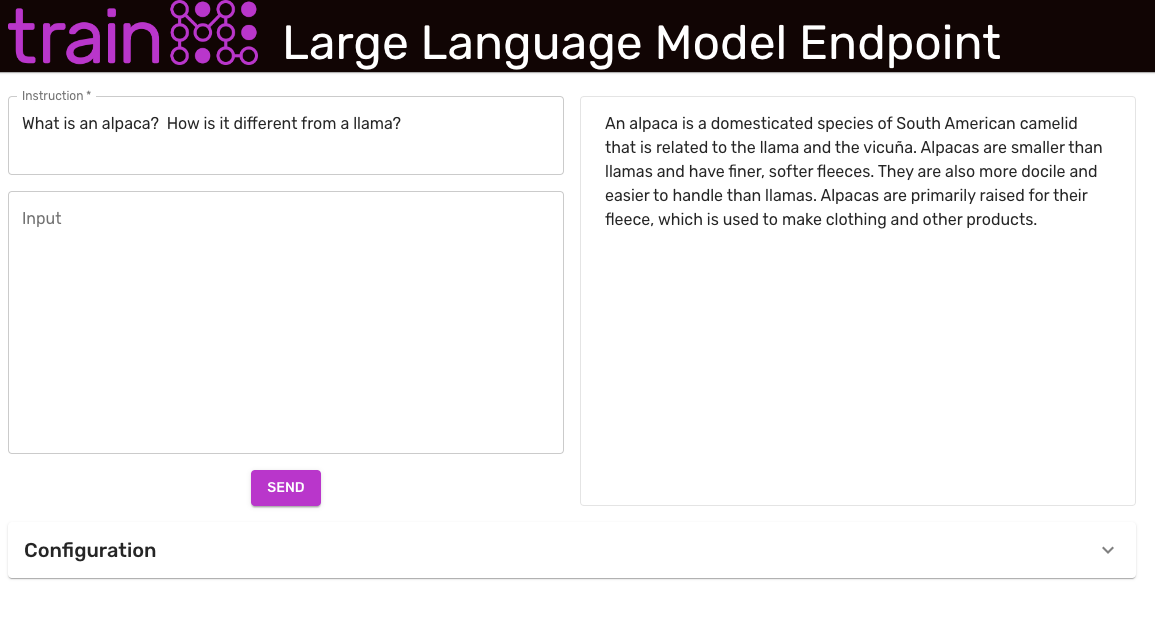
To deploy the endpoint, clone the example repo and run the deploy_endpoint.py script. Specify the name of the newly trained checkpoint as the --checkpoint argument.
git clone https://github.com/proxiML/alpaca-llm-fine-tuning-example
cd alpaca-llm-fine-tuning-example
python deploy_endpoint.py --checkpoint alpaca
The default configuration of this endpoint will incur a charge of 1.96 credits per hour as long as it is in the running status.
Once the endpoint is running, the script will output the endpoint URL. To launch the front-end, run the following:
cd front-end
npm install
npm start
This will open a web browser to http://localhost:3000 and load the example front end. Enter the endpoint URL from the above section in the Endpoint Address field, modify any other configuration settings, and click Update at the bottom of the configuration section.
When the endpoint first starts, it loads the checkpoint into the GPU memory. This process can take a few minutes. The endpoint will be ready to accept requests when the message Uvicorn running on http://0.0.0.0:80 appears in the Endpoint Execution Logs.
The example front-end and inference code enforce the same prompt format that is used to train the model. The Instruction field is required. The Input field is used for tasks where the context is needed. For example, if the Instruction is "Summarize this article", the Input field should contain the article.
The tokenizer used in this example is limited to 512 tokens. For best results, ensure your instruction/input combination does not exceed this limit.
When you are done experimenting, be sure to stop the endpoint from the Endpoint Dashboard or run the following command:
proximl job stop "Instruction-Trained LLM Endpoint Example"